Simple Oracle Document Access (SODA) set of APIs that allow you to create collection of documents in Oracle Database, so that later you can retrieve/query those documents. Using SODA implementation you can perform CRUD (create,read,update,delete) on documents. Document can be of any MIME type, in this blog we will focus on JSON.
There are separate SODA implementations available for languages like Java, Python, PL/SQL & C etc. however SODA for REST can be accessed from all those languages which support REST framework. Refer Oracle documentation for other implementation : Oracle SODA.
In this blog we will explore SODA for Python implementation. We will see how we can store/retrieve/filter JSON document in Oracle Database using Python. Oracle Database supports storing and querying JSON data natively.
Refer this blog for understanding JSON: What is JSON?
Prerequisite: Oracle Client 18.3 or higher, Oracle Database 18.1 or higher required for SODA. After that assign SODA_APP role to the database user in which you are going to create SODA collections.
-- Check client version using below query
SELECT distinct client_version
FROM v$session_connect_info
WHERE sid = SYS_CONTEXT('USERENV', 'SID');
-- Check database version using below query
SELECT * FROM v$version;
--or
SELECT * FROM v$instance;
-- SODA grant
GRANT SODA_APP TO <DB-USER>;
I’m using Oracle 19c Database, Python3 & cx_Oracle version 8. SODA is part of Oracle Python module cx_Oracle no need to install any other module.

Other Python Module used: configparser, json & requests.
SODA Collection
Soda collection is nothing but a database table. Collections contains document which can be represent as row of database table. createCollection method create a new collection in database & if collection already exists its just open without error.
SodaDatabase.createCollection(name, metadata=None, mapMode=False)
Lets create one simple collection providing only name argument.
print('Starting session...')
try:
dsn = cx_Oracle.makedsn(hostname, port, service_name=servicename)
conn = cx_Oracle.connect(username,password,dsn,encoding=encoding)
print('Connected:' + conn.version)
soda = conn.getSodaDatabase()
collection = soda.createCollection("first_collection")
conn.close()
print('connection closed...')
except cx_Oracle.Error as e:
print('Error:', e)
Collection FIRST_COLLECTION i.e. created using Python code: See below objects created by default in the database: Table, Index & Object

Collection Metadata: ‘FIRST_COLLECTION’

As metadata argument is not specified at the time of collection creation. Hence by default Oracle created a collection that support JSON document only & uses system generated keys. You can also provide metadata at the time of collection creation: Refer soda-collection-metadata-components-reference.
See below “JSON_DOCUMENT” constraint added automatically. You cannot store non json document in this collection, it will raise exception.

Insert Documents
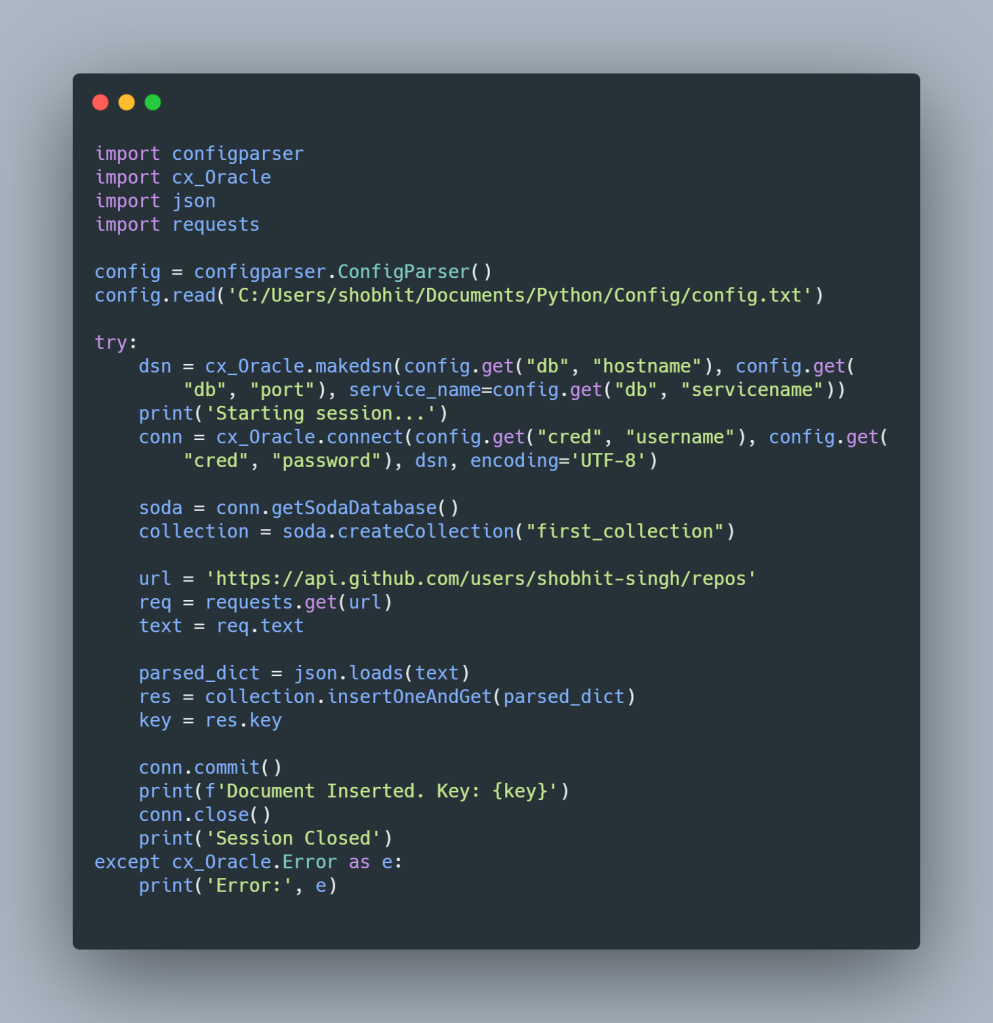
Let’s insert some JSON document in this collection “FIRST_COLLECTION”. Here we have used GitHub free API to fetch some JSON data using request module.
We will use insertOne method to insert document. Input argument must be a SODA document or a dictionary or list. Refer below how to create a SODA document.
print('Starting session...')
try:
dsn = cx_Oracle.makedsn(hostname, port, service_name=servicename)
conn = cx_Oracle.connect(username,password,dsn,encoding=encoding)
print('Connected:' + conn.version)
soda = conn.getSodaDatabase()
collection = soda.createCollection("first_collection")
url = 'https://api.github.com/users/shobhit-singh/repos'
req = requests.get(url)
text = req.text
parsed_dict = json.loads(text)
collection.insertOne(parsed_dict)
conn.close()
print('connection closed...')
except cx_Oracle.Error as e:
print('Error:', e)

A document is created in the table FIRST_COLLECTION: Refer JSON_DOCUMENT column for JSON data.

Code snippet for inserting json document using file:
try:
dsn = cx_Oracle.makedsn(hostname, port, service_name=servicename)
conn = cx_Oracle.connect(username,password,dsn,encoding=encoding)
print('Connected:' + conn.version)
soda = conn.getSodaDatabase()
collection = soda.createCollection("first_collection")
with open('jsonndata.json') as f:
data = json.load(f)
collection.insertOne(data)
conn.commit()
conn.close()
#print('connection closed...')
except cx_Oracle.Error as e:
print('Error:', e)
There are other ways also by which you can insert document in collection. Like insertOneAndGet, insertMany etc. Refer api_manual/soda
Get Collection Names
To get all collection names present in database. Use getCollectionNames method:
print('Starting session...')
try:
dsn = cx_Oracle.makedsn(hostname, port, service_name=servicename)
conn = cx_Oracle.connect(username,password,dsn,encoding=encoding)
print('Connected:' + conn.version)
soda = conn.getSodaDatabase()
name = soda.getCollectionNames(limit=5)
print(name)
conn.close()
print('connection closed...')
except cx_Oracle.Error as e:
print('Error:', e)

There are various method available for collections like drop collection, find, truncate etc. Refer this link for details : soda-collection-object
Printing metadata of collection
print('Starting session...')
try:
dsn = cx_Oracle.makedsn(hostname, port, service_name=servicename)
conn = cx_Oracle.connect(username,password,dsn,encoding=encoding)
print('Connected:' + conn.version)
soda = conn.getSodaDatabase()
coll = soda.openCollection("git_repos")
print(coll.metadata)
conn.close()
print('connection closed...')
except cx_Oracle.Error as e:
print('Error:', e)

Get all documents inside a collection
print('Starting session...')
try:
dsn = cx_Oracle.makedsn(hostname, port, service_name=servicename)
conn = cx_Oracle.connect(username,password,dsn,encoding=encoding)
print('Connected:' + conn.version)
soda = conn.getSodaDatabase()
coll = soda.openCollection("first_collection")
doc = coll.find()
print(doc.getDocuments())
conn.close()
print('connection closed...')
except cx_Oracle.Error as e:
print('Error:', e)


Retrieving Data
Retrieve JSON data from the document. Let’s just print all GitHub repo names present in that JSON.
print('Starting session...')
try:
dsn = cx_Oracle.makedsn(hostname, port, service_name=servicename)
conn = cx_Oracle.connect(username,password,dsn,encoding=encoding)
print('Connected:' + conn.version)
soda = conn.getSodaDatabase()
coll = soda.openCollection("first_collection")
doc = coll.find()
docs = doc.getDocuments()
res = docs[0].getContent()
for i in res:
print (i["name"])
# dumping complete data as json file
json.dump(res, open ('data.json', 'w'), indent=4)
conn.close()
print('connection closed...')
except cx_Oracle.Error as e:
print('Error:', e)

Filtering JSON documents data
Filter documents records in collection on the basis of some input dictionary or JSON string. Filter specification is also called a query-by-example (QBE).
Refer this guide for filter specification details. overview-soda-filter-specifications-qbes
try:
dsn = cx_Oracle.makedsn(hostname, port, service_name=servicename)
conn = cx_Oracle.connect(username,password,dsn,encoding=encoding)
print('Connected:' + conn.version)
soda = conn.getSodaDatabase()
coll = soda.openCollection("first_collection")
doc = coll.find()
docs = doc.filter({"Numbers": {"0": "Zero", "1": "One"}})
#docs = doc.filter({"name": "BigDataEnthusiast"})
print( 'Count' ,docs.count())
print( 'Doc Key:' , docs.getDocuments())
conn.close()
print('connection closed...')
except cx_Oracle.Error as e:
print('Error:', e)


There are so many method available for collections/documents. You can refer below mentioned cx_orale documentation for more learning.
Refer GitHub link all code used in blog: github.com/shobhit-singh/Python-Programs/tree/master/cx_oracle_soda
References:
- https://cx-oracle.readthedocs.io/en/latest/user_guide/soda.html
- https://cx-oracle.readthedocs.io/en/latest/api_manual/soda.html#
- https://docs.oracle.com/en/database/oracle/simple-oracle-document-access/adsdi/index.html
Thanks!
Happy Learning! Your feedback would be appreciated!