In this blog we will explore some more latest Oracle SQL scenario questions. Here we will cover analytical functions list aggregate, date functions, union all, pivot & prime numbers. Breaking single string to multiple rows using dual, rownum or level providing the separator.
- Part 1 Blog Link: Oracle SQL Scenario Questions Part 1 Topics: regex, pivot, binary tree and other Oops related PL/SQL questions.
- Part 3 Blog Link: Oracle SQL – Scenario Questions – Part 3 : Topics : RPAD, PLAD, Null Function, Instr, Substr, regex_substr, translate.
- Part 4 Blog Link: Oracle SQL – Scenario Questions Part 4 Topic: Unique Index, Non-Unique Index & Functional Index. etc.
Scenario 1. In below example remove the duplicate. Example: Records 1 & 2 are identical.
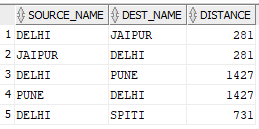
CREATE TABLE "DISTANCE"
(
"SOURCE_NAME" VARCHAR2(20 BYTE),
"DEST_NAME" VARCHAR2(20 BYTE),
"DISTANCE" NUMBER
);
Insert into DISTANCE (SOURCE_NAME,DEST_NAME,DISTANCE) values ('DELHI','JAIPUR',281);
Insert into DISTANCE (SOURCE_NAME,DEST_NAME,DISTANCE) values ('JAIPUR','DELHI',281);
Insert into DISTANCE (SOURCE_NAME,DEST_NAME,DISTANCE) values ('DELHI','PUNE',1427);
Insert into DISTANCE (SOURCE_NAME,DEST_NAME,DISTANCE) values ('PUNE','DELHI',1427);
Insert into DISTANCE (SOURCE_NAME,DEST_NAME,DISTANCE) values ('DELHI','SPITI',731);
COMMIT;
Solution: You can use the LEAST/GREATEST function to find out the dupes.
SELECT d.*, row_number() over (partition BY LEAST(SOURCE_NAME, DEST_NAME), GREATEST(SOURCE_NAME, DEST_NAME), distance order by distance )AS RNUM FROM DISTANCE d;

From this data set you can filter the rows using the RNUM column to fetch distinct rows.
WITH data_set AS (SELECT d.*, row_number() over (partition BY LEAST(SOURCE_NAME, DEST_NAME), GREATEST(SOURCE_NAME, DEST_NAME), distance order by distance ) AS RNUM FROM DISTANCE d ) SELECT * FROM data_set WHERE RNUM =1;

Scenario 2. In below example customer data is present for product with dates. Fetch the customer who came in all months of quarter at least once. Like Jan, Feb, Mar or Apr, May, June etc. Notice in below data-set C1 & C3 came in all months of quarter Q1 & Q2 respectively.

Solution: You can use the date functions to find out the months & quarter.
SELECT CUST_ID, listagg (TO_CHAR(BILL_DATE,'MM'),'||') within GROUP ( ORDER BY BILL_DATE) months_name, TO_CHAR(BILL_DATE,'q') FROM SALES GROUP BY CUST_ID, TO_CHAR(BILL_DATE,'YYYY'), TO_CHAR(BILL_DATE,'q');
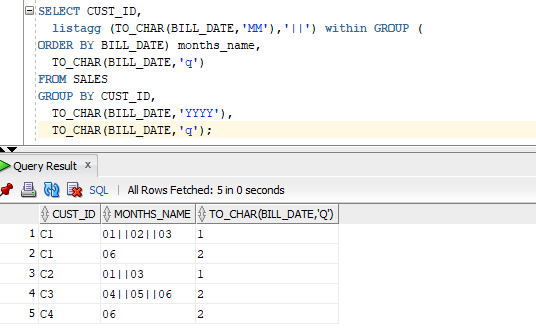
WITH dataset AS
(SELECT CUST_ID,
listagg (TO_CHAR(BILL_DATE,'MM'),'||') within GROUP (
ORDER BY BILL_DATE) months_name,
TO_CHAR(BILL_DATE,'YYYY') year_,
TO_CHAR(BILL_DATE,'q') quarter_
FROM SALES
GROUP BY CUST_ID,
TO_CHAR(BILL_DATE,'YYYY'),
TO_CHAR(BILL_DATE,'q')
)
SELECT *
FROM dataset
WHERE months_name IN ('01||02||03','04||05||06','07||02||09','10||11||12') ;

Scenario 3. Output of this SQL: Select count(1), SUM(1) from dual where 1=2;
Select count(1), SUM(1) from dual where 1=2;

Scenario 4. Print 1st day of Month, Last Day, Mid, Week, Quarter for given date.
WITH dataset AS
(SELECT to_date('10-JAN-2019','dd-mon-yyyy') date_ FROM dual
union
SELECT to_date('20-FEB-2019','dd-mon-yyyy') date_ FROM dual
union
SELECT to_date('05-JUN-2019','dd-mon-yyyy') date_ FROM dual
)
SELECT to_char(date_,'DD-MM-YYYY'), to_char(date_,'Q') Quarter ,to_char(date_,'W') week,
trunc((date_),'MM') FIRST_DATE_OF_MONTH, last_day(date_) LAST_DATE_OF_MONTH
FROM dataset;

Print Day of the date:

Scenario 5. In below example you have to print date twice. See sample date.
Input: ![]() Output Required:
Output Required: ![]()
Solution:
WITH data_set AS ( SELECT id_ FROM dataset UNION ALL SELECT id_ FROM dataset ) SELECT * FROM data_set ORDER BY 1;

Scenario 6. In below example you have ~ tilde separated date in column VAL. You have to break the string using SQL like below. Refer required output screenshot.
Input:  Required Output:
Required Output: 
CREATE TABLE DATASET ( ID_ NUMBER, VAL VARCHAR2(100)); INSERT INTO DATASET VALUES (1, 'A~B~C~D'); INSERT INTO DATASET VALUES (2, 'X~Y~Z'); INSERT INTO DATASET VALUES (5, 'K'); COMMIT;
Solution: You can use the level also instead of rownum to generate numbers.

Scenario: 6.1 [Updated later]
CREATE TABLE DATASET ( ID_ NUMBER, VAL VARCHAR2(100));
INSERT INTO DATASET VALUES (1, 'Hello~World~Some~Value');
INSERT INTO DATASET VALUES (2, 'XXXXX~YYY~ZZZ');
INSERT INTO DATASET VALUES (5, 'K');
COMMIT;
Output Required:

Solution 6.1:
WITH TAB AS
(SELECT ID_,VAL,regexp_count(VAL,'~')+1 cnt FROM DATASET)
SELECT DISTINCT ID_,regexp_substr(VAL,'[^~]+',1,level) VAL
FROM TAB CONNECT BY LEVEL<=cnt ORDER BY 1;

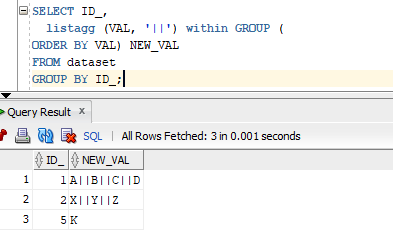
Scenario 7. Similar to Scenario 6, In below example you have data in VAL column & you have bring it in one row separated by double pipe ||.
Input : Required Output: 
DROP TABLE DATASET;
CREATE TABLE DATASET ( ID_ NUMBER, VAL VARCHAR2(100));
INSERT INTO "DATASET" (ID_, VAL) VALUES ('1', 'A');
INSERT INTO "DATASET" (ID_, VAL) VALUES ('1', 'B');
INSERT INTO "DATASET" (ID_, VAL) VALUES ('1', 'C');
INSERT INTO "DATASET" (ID_, VAL) VALUES ('1', 'D');
INSERT INTO "DATASET" (ID_, VAL) VALUES ('2', 'Y');
INSERT INTO "DATASET" (ID_, VAL) VALUES ('2', 'Z');
INSERT INTO "DATASET" (ID_, VAL) VALUES ('2', 'X');
INSERT INTO "DATASET" (ID_, VAL) VALUES ('5', 'K');
COMMIT;
Solution:
SELECT ID_, listagg (VAL, '||') within GROUP ( ORDER BY VAL) NEW_VAL FROM dataset GROUP BY ID_;
Scenario 8. Rotating rows to column, see below screenshot.
Input: 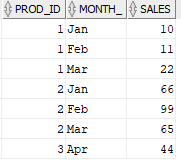 Output:
Output: 
Solution : Using Pivot Clause
SELECT *
FROM
(SELECT prod_id, month_, sales FROM sales_data
) pivot( MAX(sales) FOR month_ IN ('Jan' AS JAN, 'Feb' AS FEB, 'Mar' AS MAR, 'Apr' AS APR) );

Scenario 9 : Print prime numbers using SQL
WITH a AS ( SELECT rownum rn FROM dual CONNECT BY rownum <=20 ), b AS (SELECT rownum rn FROM dual CONNECT BY rownum =b.rn ), prime_num AS (SELECT rn FROM div WHERE mod_=0 GROUP BY rn HAVING COUNT(rn1)=2 ORDER BY 1 ) SELECT * FROM prime_num;

Scenario 10.1: Running balance sum of transactions in table for single account.
Input Data:

Output Required :

drop table SAMPLE_DATA;
CREATE TABLE SAMPLE_DATA
( "TRANSACTION_ID" NUMBER,
"TRANSACTION_DATE" DATE,
"ACCOUNT_ID" VARCHAR2(15 CHAR),
"TRANSACTION_TYPE" VARCHAR2(15 CHAR),
"TRANSACTION_CHANNEL" VARCHAR2(15 CHAR),
"AMOUNT" NUMBER
);
Insert into SAMPLE_DATA (TRANSACTION_ID,TRANSACTION_DATE,ACCOUNT_ID,TRANSACTION_TYPE,TRANSACTION_CHANNEL,AMOUNT) values (1,'01-MAR-2015','Ac1234','DEPOSIT','NEFT',1000);
Insert into SAMPLE_DATA (TRANSACTION_ID,TRANSACTION_DATE,ACCOUNT_ID,TRANSACTION_TYPE,TRANSACTION_CHANNEL,AMOUNT) values (2,'01-MAR-2015','Ac1234','DEPOSIT','NEFT',2000);
Insert into SAMPLE_DATA (TRANSACTION_ID,TRANSACTION_DATE,ACCOUNT_ID,TRANSACTION_TYPE,TRANSACTION_CHANNEL,AMOUNT) values (3,'02-MAR-2015','Ac1234','WITHDRAWAL','ATM',500);
Insert into SAMPLE_DATA (TRANSACTION_ID,TRANSACTION_DATE,ACCOUNT_ID,TRANSACTION_TYPE,TRANSACTION_CHANNEL,AMOUNT) values (4,'03-MAR-2015','Ac1234','WITHDRAWAL','NEFT',100);
Insert into SAMPLE_DATA (TRANSACTION_ID,TRANSACTION_DATE,ACCOUNT_ID,TRANSACTION_TYPE,TRANSACTION_CHANNEL,AMOUNT) values (5,'04-MAR-2015','Ac1234','WITHDRAWAL','CHQ',200);
Insert into SAMPLE_DATA (TRANSACTION_ID,TRANSACTION_DATE,ACCOUNT_ID,TRANSACTION_TYPE,TRANSACTION_CHANNEL,AMOUNT) values (6,'04-MAR-2015','Ac1234','DEPOSIT','CHQ',1000);
Insert into SAMPLE_DATA (TRANSACTION_ID,TRANSACTION_DATE,ACCOUNT_ID,TRANSACTION_TYPE,TRANSACTION_CHANNEL,AMOUNT) values (7,'05-MAR-2015','Ac1234','DEPOSIT','CHQ',1000);
Insert into SAMPLE_DATA (TRANSACTION_ID,TRANSACTION_DATE,ACCOUNT_ID,TRANSACTION_TYPE,TRANSACTION_CHANNEL,AMOUNT) values (8,'06-MAR-2015','Ac1234','WITHDRAWAL','ATM',1000);
commit;
Solution Scenario 10.1:
select TRANSACTION_DATE,ACCOUNT_ID, TRANSACTION_TYPE,TRANSACTION_CHANNEL, AMOUNT ,
sum ( case when TRANSACTION_TYPE='DEPOSIT' then amount when TRANSACTION_TYPE='WITHDRAWAL' then -amount end )
over (order by TRANSACTION_ID) "BALANCE"
from SAMPLE_DATA order by 1;

Scenario 10.2: Running balance sum of transactions in table for multiple accounts.
-- first use ddl & dml from question no 10.
Insert into SAMPLE_DATA (TRANSACTION_ID,TRANSACTION_DATE,ACCOUNT_ID,TRANSACTION_TYPE,TRANSACTION_CHANNEL,AMOUNT) values (1,'01-MAR-2015','Ac1235','DEPOSIT','NEFT',1000);
Insert into SAMPLE_DATA (TRANSACTION_ID,TRANSACTION_DATE,ACCOUNT_ID,TRANSACTION_TYPE,TRANSACTION_CHANNEL,AMOUNT) values (2,'01-MAR-2015','Ac1235','DEPOSIT','NEFT',2000);
Insert into SAMPLE_DATA (TRANSACTION_ID,TRANSACTION_DATE,ACCOUNT_ID,TRANSACTION_TYPE,TRANSACTION_CHANNEL,AMOUNT) values (3,'02-MAR-2015','Ac1235','WITHDRAWAL','ATM',500);
Insert into SAMPLE_DATA (TRANSACTION_ID,TRANSACTION_DATE,ACCOUNT_ID,TRANSACTION_TYPE,TRANSACTION_CHANNEL,AMOUNT) values (4,'03-MAR-2015','Ac1235','WITHDRAWAL','NEFT',100);
Insert into SAMPLE_DATA (TRANSACTION_ID,TRANSACTION_DATE,ACCOUNT_ID,TRANSACTION_TYPE,TRANSACTION_CHANNEL,AMOUNT) values (5,'04-MAR-2015','Ac1235','DEPOSIT','NEFT',500);
commit;
Input: Transactions of multiple accounts.

Solution 10.2:
select TRANSACTION_DATE,ACCOUNT_ID, TRANSACTION_TYPE,TRANSACTION_CHANNEL, AMOUNT ,
sum ( case when TRANSACTION_TYPE='DEPOSIT' then amount when TRANSACTION_TYPE='WITHDRAWAL' then -amount end )
over (partition by account_id order by account_id, TRANSACTION_ID) "BALANCE"
from SAMPLE_DATA order by 2,1;

Visit below blogs for more scenario questions.
- Oracle SQL – Scenario Questions Part 4
- Oracle SQL Scenario Questions – Part 3
- Oracle SQL Scenario Questions – Part 1
Thanks!
Happy Learning! Your feedback would be appreciated!
Follow @shobhitsinghIN
Scenario 6 : optimized query would be :
select id_, regexp_substr(val,'[^~]+’, 1, level)
from dataset
connect by regexp_substr(val, ‘[^~]+’, 1, level) is not null;
Kind regards,
Priyanka
LikeLiked by 1 person
Thanks for your input.
I have tried your query, it was giving duplicates records in output.
On top of this query we can go with group by or distinct (thought distinct is not recommended for huge records) to pick unique records. Or may be analytical query to fetch 1 record per group.
LikeLike
For scenario 6:
WITH TAB AS
(SELECT ID,REPLACE(VAL,’~’,”) STR FROM DATASET)
SELECT DISTINCT ID,SUBSTR(STR,LEVEL,1) FROM TAB CONNECT BY LEVEL<=LENGTH(STR) ORDER BY 1;
LikeLiked by 1 person
Thanks for your solution Mahesh. It will work only if the value is of char length 1.
Typically in real word scenario, values can come of variable length. So solution must be robust, which can handle all scenarios.
Let say now data is like this:
CREATE TABLE DATASET ( ID_ NUMBER, VAL VARCHAR2(100));
INSERT INTO DATASET VALUES (1, ‘Hello~World~Some~Value’);
INSERT INTO DATASET VALUES (2, ‘XXXXX~YYY~ZZZ’);
INSERT INTO DATASET VALUES (5, ‘K’);
COMMIT;
LikeLike
What about this for scenario 6:
select id_,
regexp_substr(val,'[^~]+’, 1, level) val
from dataset
connect by level <= regexp_count(val,'[^~]+')
and prior id_ = id_
and prior sys_guid() is not null
LikeLike
FOR SCENARIO 2
—————————————————————————-
WITH CUSTOMER_DATA AS
(
SELECT DISTINCT CUSTOMER,TO_CHAR(TO_DATE(BILL_DT,’DD-MM-YY’),’MM’) MTH,TO_CHAR(TO_DATE(BILL_DT,’DD-MM-YY’),’q’)QTR
FROM DATA
)
SELECT CUSTOMER,COUNT(1)
FROM CUSTOMER_DATA
GROUP BY CUSTOMER,QTR
HAVING COUNT(QTR)=3
LikeLike