Folks,
In this blog we will do the sentimental analysis of Trump & Clinton Tweets using R!
We will use Microsoft Cognitive Services (Text Analytics API) in R to calculate sentimental scores of tweets!
Step 1) Twitter Data Extraction
Extract tweets of Trump & Clinton using twitteR Package.
library(twitteR)
setup_twitter_oauth(Consumer_API_Key, Consumer_API_Secret, Access_Token, Access_Token_Secret)
clinton_tweets = searchTwitter("Hillary Clinton+@HillaryClinton", n=200, lang="en")
trump_tweets = searchTwitter("Donald Trump+@realDonaldTrump", n=200, lang="en")
trump_tweets_df = do.call("rbind", lapply(trump_tweets, as.data.frame))
trump_tweets_df = subset(trump_tweets_df, select = c(text))
clinton_tweets_df = do.call("rbind", lapply(clinton_tweets, as.data.frame))
clinton_tweets_df = subset(clinton_tweets_df, select = c(text))
If you are new to twitteR package, please visit this blog & learn how to setup twitter application & Oauth in R.
Step 2) Cleaning of Tweets
Cleaning both dataframe – trump_tweets_df & clinton_tweets_df.
Below is the just sample code for cleaning text in R.
# Removing blank spaces, punctuation, links, extra spaces, special characters and other unwanted things.
clinton_tweets$text = gsub("[:blank:]", "", clinton_tweets$text)
clinton_tweets$text = gsub("[[:punct:]]", "", clinton_tweets$text)
clinton_tweets$text = gsub("[:cntrl:]", "", clinton_tweets$text)
clinton_tweets$text = gsub("[[:digit:]]", "", clinton_tweets$text)
clinton_tweets$text = gsub("[:blank:]", "", clinton_tweets$text)
clinton_tweets$text = gsub("(RT|via)((?:\\b\\W*@\\w+)+)", " ", clinton_tweets$text)
clinton_tweets$text = gsub("@\\w+", "", clinton_tweets$text)
clinton_tweets$text = gsub("http\\w+", "", clinton_tweets$text)
# Removing Duplicate tweets
clinton_tweets["DuplicateFlag"] = duplicated(clinton_tweets$text)
clinton_tweets = subset(clinton_tweets, clinton_tweets$DuplicateFlag=="FALSE")
clinton_tweets = subset(clinton_tweets, select = -c(DuplicateFlag))
Here is the snapshot of cleaned data frames trump_tweets_df & clinton_tweets_df.
Step 3) Calculate Sentimental Scores
We will use Microsoft Cognitive Services (Text Analytics API) in R to calculate sentimental scores of tweets. If you are new to Microsoft Cognitive Services, please visit this blog .
Calculating sentimental scores for trump_tweets_df –
library(jsonlite)
library(httr)
# Creating the request body for Text Analytics API
trump_tweets_df["language"] = "en"
trump_tweets_df["id"] = seq.int(nrow(trump_tweets_df))
request_body_trump = trump_tweets_df[c(2,3,1)]
# Converting tweets dataframe into JSON
request_body_json_trump = toJSON(list(documents = request_body_trump))
# Calling text analytics API
result_trump = POST("https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/sentiment",
body = request_body_json_trump,
add_headers(.headers = c("Content-Type"="application/json","Ocp-Apim-Subscription-Key"="my_Subscription-Key")))
Output = content(result_trump)
score_output_trump = data.frame(matrix(unlist(Output), nrow=100, byrow=T))
score_output_trump$X1 = as.numeric(as.character(score_output_trump$X1))
score_output_trump$X1 = as.numeric(as.character(score_output_trump$X1)) *10
score_output_trump["Candidate"] = "Trump"
Calculating sentimental scores for clinton_tweets_df –
# Creating the request body for Text Analytics API
clinton_tweets_df["language"] = "en"
clinton_tweets_df["id"] = seq.int(nrow(clinton_tweets_df))
request_body_clinton = clinton_tweets_df[c(2,3,1)]
# Converting tweets dataframe into JSON
request_body_json_clinton = toJSON(list(documents = request_body_clinton))
result_clinton = POST("https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/sentiment",
body = request_body_json_clinton,
add_headers(.headers = c("Content-Type"="application/json","Ocp-Apim-Subscription-Key"="my-Subscription-Key")))
Output_clinton = content(result_clinton)
score_output_clinton = data.frame(matrix(unlist(Output_clinton), nrow=100, byrow=T))
score_output_clinton$X1 = as.numeric(as.character(score_output_clinton$X1))
score_output_clinton$X1 = as.numeric(as.character(score_output_clinton$X1)) *10
score_output_clinton["Candidate"] = "Clinton"
Here is the snapshot of sentimental scores of trump_tweets_df & clinton_tweets_df.
Where X1 is Sentimntal Score & Where X2 is ID of tweets present in dataframe.
Here scores close to 10 indicate positive sentiment, while scores close to 1 indicate negative sentiment
Snapshot –

Step 4) Sentimental Analysis Output
Boxplot for the sentimental scores.
final_score = rbind(score_output_clinton,score_output_trump)
library(ggplot2)
cols = c("#7CAE00", "#00BFC4")
names(cols) = c("Clinton", "Trump")
# boxplot
ggplot(final_score, aes(x=final_score$Candidate, y=X1, group=final_score$Candidate)) +
geom_boxplot(aes(fill=final_score$Candidate)) +
scale_fill_manual(values=cols) +
geom_jitter(colour="gray40",
position=position_jitter(width=0.5), alpha=0.3)
Box Plot –
Here you can see that Trump Median(7.1) > Hillary Median (6.7)
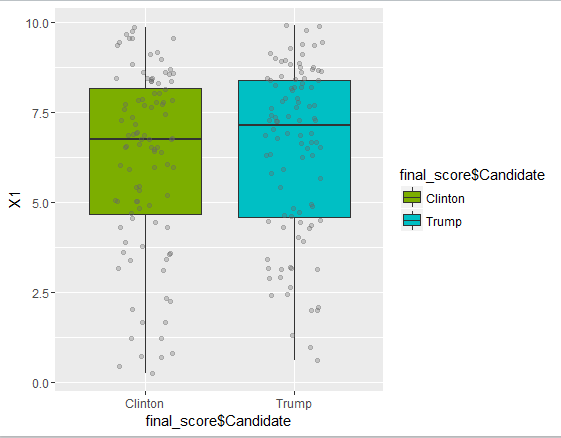
Here scores close to 10 indicate positive sentiment, while scores close to 1 indicate negative sentiment
Summary of Sentimental Scores –

Thanks!
Happy Learning! Your feedback would be appreciated!
Follow @shobhitsinghIN
in Step 2) you’ve missed _df in clinton_tweets -> there is no clinton_tweets$text, there is clinton_tweets_df$text
LikeLiked by 1 person
Yes you are correct, it is because i have provided only reference cleaning code in my blog. Thanks!
LikeLike
i got thiserror : Error in tweets1[“DuplicateFlag”] = duplicated(tweets1$text) :
replacement has length zero how can i correctit??
LikeLike
HI ,
I got below mentioned error while executing below-mentioned line …Secondly in your code u have mentioned removal of duplicates for clinton not for trump ??
LIne NO
clinton_tweets = subset(clinton_tweets, select = -c(DuplicateFlag))
Details of Error
Error in subset.default(clinton_tweets, select = c(DuplicateFlag)) :
argument “subset” is missing, with no default
LikeLike
Yes i have provided only sample code for cleaning data. For both data frames Clinton & trump we have to perform similar cleaning process.
Regarding error – please check your dataframe & provide column names accordingly.
LikeLike
Hi Shobhit,
I am trying to do twitter data mining in R.However, when I am trying to connect using access keys, I am getting the OAuth authentication error.Please help.I can also sharing the code I am using
library(twitteR)
Consumer_API_Key<-'dACKFLWwCVF8Y9Ji7'
Consumer_API_Secret<-'YEBmYl7jQNU509Wndqv0tDNwN7xW8Tjmk'
Access_Token<-'113567783-Kuy7T3cQSgUNioyycKkwLskNh'
Access_Token_Secret<-'VI3ROoOy7bS47Njn3IbSy8PfTqNFUXV'
setup_twitter_oauth(Consumer_API_Key, Consumer_API_Secret, Access_Token, Access_Token_Secret)
LikeLike
Hi , small question … why u have not use corpus function for data cleansing ??
LikeLike
HI
https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/sentiment this api return
{
“statusCode”: 404,
“message”: “Resource not found”
}
LikeLike
the url depends on your subscription to microsoft coginitive api. you also need to append key to get the result
LikeLike